


















")










, cel mai nou serial de la producătorii Yellowstone, a fost reînnoit pentru al doilea sezon pe SkyShowtime")

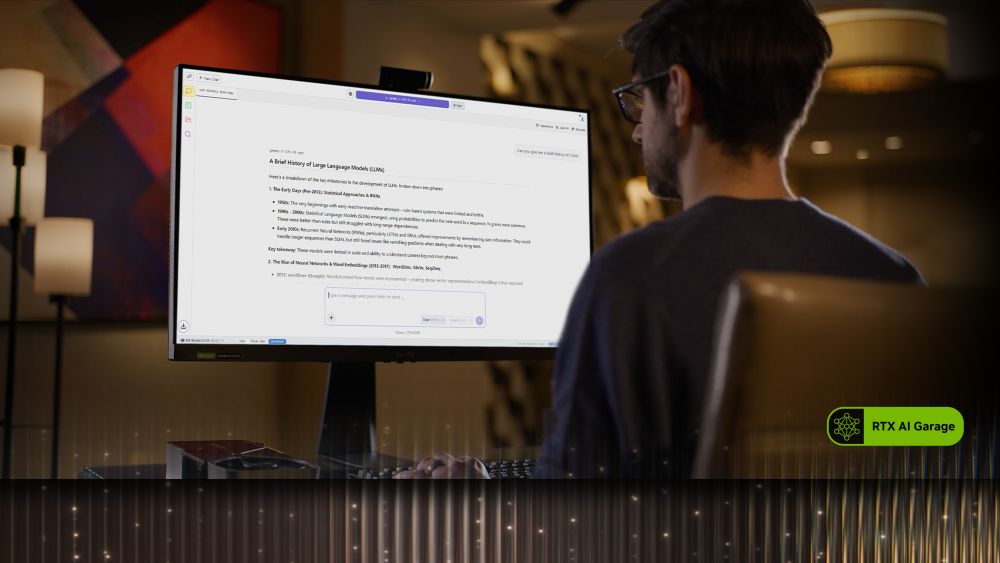
Tot mai mulți utilizatori aleg să ruleze modele de limbaj mari (LLM) direct pe PC-urile lor pentru a reduce costurile abonamentelor și pentru a avea mai multă confidențialitate și control asupra proiectelor. Odată cu apariția unor modele open-weight avansate și a unor instrumente gratuite care permit rularea lor local, devine mai simplu ca oricând să experimentezi AI-ul direct pe laptop sau desktop. Plăcile grafice RTX accelerează aceste experiențe, oferind performanțe rapide și fluide. În plus, cu noile actualizări Project G-Assist, utilizatorii de laptop pot începe să folosească atât comenzi vocale, cât și text bazate pe AI pentru a-și controla PC-ul.
Cel mai recent articol RTX AI Garage de la NVIDIA arată cum studenții, pasionații de AI și dezvoltatorii pot începe chiar astăzi să utilizeze LLM-uri pe PC-uri:
-
Ollama: Una dintre cele mai accesibile modalități de a începe. Acest instrument open-source oferă o interfață simplă pentru rularea și utilizarea LLM-urilor. Utilizatorii pot adăuga fișiere PDF direct în prompturi, pot purta conversații interactive și chiar pot încerca fluxuri multimodale care combină textul cu imaginile.
-
AnythingLLM: Construiește-ți propriul asistent AI. Rulează pe baza Ollama și le permite utilizatorilor să încarce notițe, prezentări sau documente pentru a crea un „tutor” capabil să genereze quiz-uri și fișe de lucru pentru cursuri, fiind privat, rapid și gratuit.
-
LM Studio: Explorează zeci de modele. Bazat pe framework-ul popular llama.cpp, oferă o interfață intuitivă pentru rularea locală a modelelor. Utilizatorii pot încărca LLM-uri diferite, pot conversa cu ele în timp real și le pot transforma în endpoint-uri API locale pentru a le integra în proiecte personalizate.
-
Project G-Assist: Controlează-ți PC-ul cu AI. Cu ultimele actualizări, utilizatorii pot ajusta prin voce sau text setările de baterie, ventilator și performanță.
Cele mai noi progrese în RTX AI pe PC includ:
-
Performanță sporită pentru Ollama pe RTX: Actualizările recente aduc până la 50% îmbunătățire a performanței pentru OpenAI gpt-oss-20B și până la 60% viteză mai mare pentru modelele Gemma 3, plus o planificare mai inteligentă a modelelor pentru reducerea problemelor de memorie și eficiență mai bună pe mai multe GPU-uri.
-
Llama.cpp și GGML optimizate pentru RTX: Actualizările recente oferă inferență mai rapidă și mai eficientă pe plăcile RTX, inclusiv suport pentru modelul NVIDIA Nemotron Nano v2 9B, Flash Attention activ și optimizări CUDA kernel.
-
G-Assist v0.1.18: Poate fi descărcat prin NVIDIA App și include noi comenzi pentru utilizatorii de laptop, precum și răspunsuri mai precise.
-
Microsoft Windows ML cu NVIDIA TensorRT pentru RTX: Oferă inferență cu până la 50% mai rapidă, implementare simplificată și suport pentru LLM-uri, modele de difuzie și alte tipuri de modele pe PC-uri cu Windows 11.
Descoperă mai multe în ediția din această săptămână a RTX AI Garage.







{kind=link}